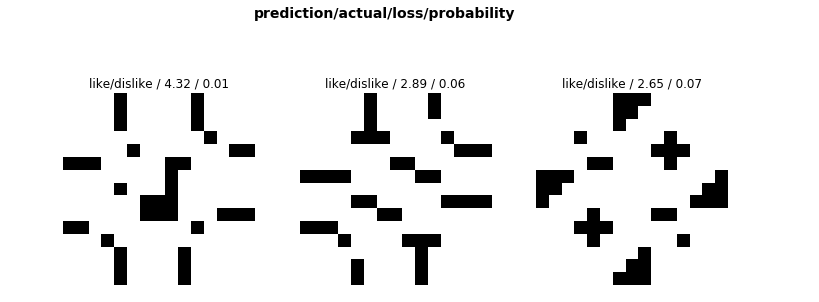
Somewhere along the way this summer I quit doing crosswords for a while. Maybe my gardening hobby took over, or I didn’t want to touch the computer after work, or perhaps pandemic has been too much of a stressor, or maybe it just felt too much of an obligation to keep up with — whatever the reason, I fell out of practice a bit. Visualized, my puzzling activity for 2022 looks like this:
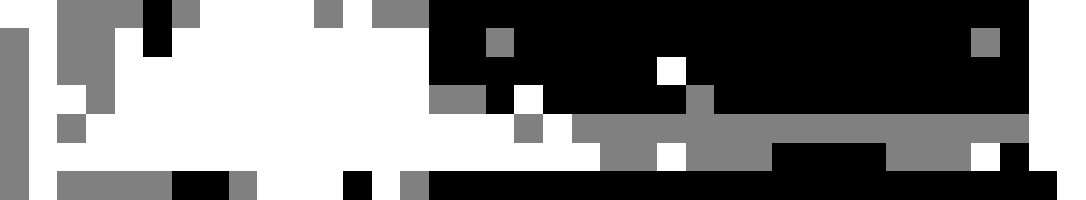
legend: white = streak meaning I solved it the day of, gray = I did it (possibly much) later, black = still haven’t opened it
I also skipped entirely the ACPT this year.
Recently, though, an LWN story about Gnome Crosswords rekindled my interest a bit. A few of the puzzles from my website have been merged into this project, and I have another few sitting around that I will polish up and submit someday.
This was a good exercise to clean up some awkward fill:
- BOB / MAKO cross to BIB / MAKI; for this rejected-from-NYT puzzle, I still felt bad about putting my own name in it; also I guess MAKI is more common for anyone who has ever eaten sushi
- PETRE [Architect of Christchurch Basilica (?!)] / GAR to PETME / GAM in this puzzle. Although GAM feels objectifying, I clued it as bygone film noir slang. Anyway PETRE was so terrible that it had to go.
- Same puzzle, AKA / OKE [Just great, in old slang (?!)] to ADA / ODE. People running Linux are quite likely to know Ada Lovelace, besides which it is in mainstream puzzles by now, and OKE is very O_o.
There are still some lousy answers in both puzzles, driven by grid shape so fixing would require a lot of work, but these tiny tweaks make them a lot less bad.
Meanwhile, I’ve completed most of the early-week puzzles over the last few weeks, chasing the 5-minute mark on Tuesday puzzles (personal best currently 5:07) and the 4-minute mark on Mondays (4:12).
The discussion in the LWN thread was about crossword file formats, and since Gnome crosswords uses ipuz, I dusted off XwordJS and added ipuz support, and even wrote a couple of test cases. For my money I still prefer XD, much the same as I prefer Markdown to HTML, which brings me back to the image at the beginning of the post.
When I was a wee lad, we would write programs to make images, and all libraries sucked in these times so we would often roll our own. As an example of sucking, this is from a real-life comment in actual code:
* We use C's setjmp/longjmp facility to return control. This means that the
* routine which calls the JPEG library must first execute a setjmp() call to
* establish the return point. We want the replacement error_exit to do a
* longjmp(). But we need to make the setjmp buffer accessible to the
* error_exit routine. To do this, we make a private extension of the
* standard JPEG error handler object. (If we were using C++, we'd say we
* were making a subclass of the regular error handler.)
Being poor students at the time, we could not afford to spend our hard-earned money on compression, decimal to binary conversion, or complex serializers, so we did the simplest possible thing that worked: we wrote out P[BGP]M text files (we were profligate when it came to disk). My little visualization was done just in this way: open up vim, a few macros later, a PGM file is born. I let gimp handle the hard work of rotating, scaling up, and converting to PNG, but ImageMagick probably would’ve worked just as well.
P2
7 38
255
128 128 128 128 128 128 255
255 255 255 255 255 255 255
[...]
There is a lot to be said for plain old text, and no, that does not include JSON.