
I had just a little bit of downtime over the last few weeks while Angeline and I reacquainted ourselves with how to take care of an infant. It’s like riding a bicycle: there are tons of things you forgot since last time.
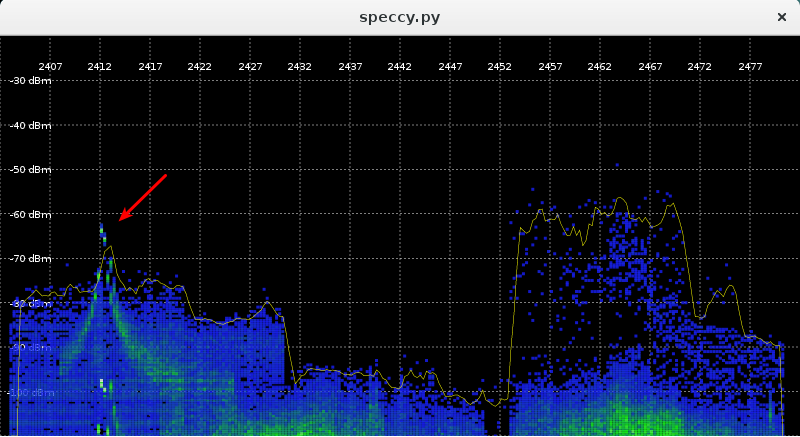
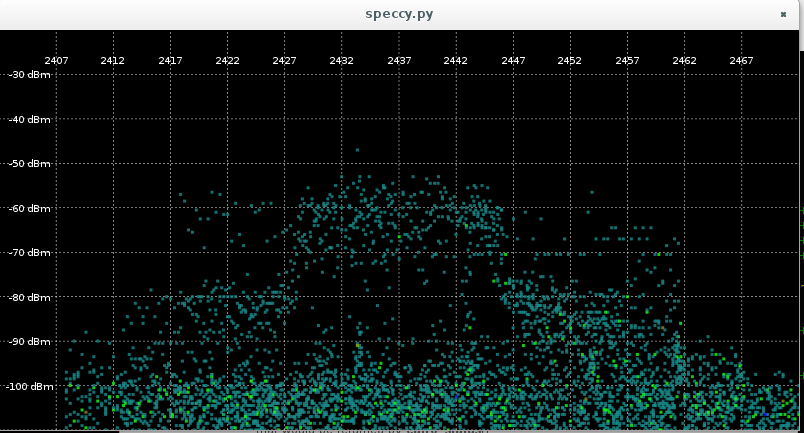
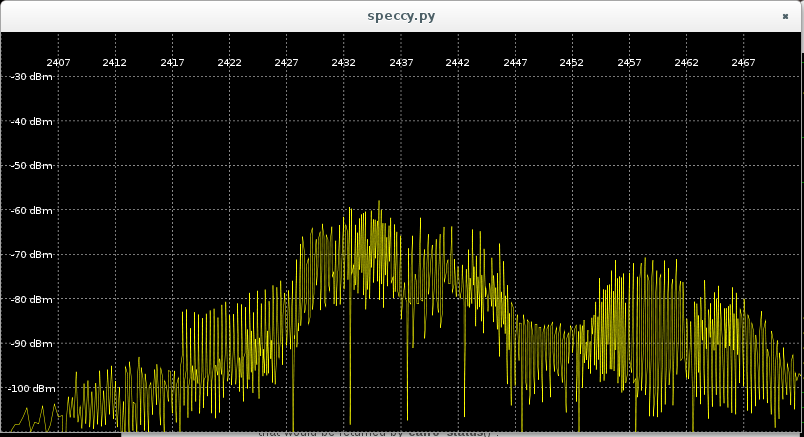
One of the long-on-my-todo-list items finally got completed: I upgraded all of my wifi routers. I have 5: an old dual band 11n router and four TP-Link 11ac units, all of which were running some oldish build of OpenWRT.
I decided the 11n router’s time has come for the trash-heap, so I put the latest stable LEDE build on one of the TP-Links and swapped it out.
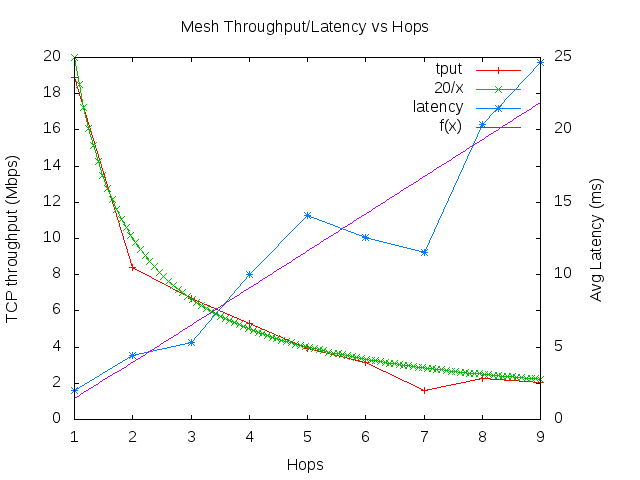
The other three are just access points without the router: they just have all the ports on the unit bridged together, connected to the router via a wired switch. I also have a mesh wifi interface up on each unit so that I could place the unit anywhere regardless of wired connectivity (though, in practice, I have wired drops everywhere so I don’t really use this.) For these, I build from source with just the required bits. I added a serial port to one of the units so I can test builds there before rolling out to the other two.
In all it was pretty painless since the LEDE build is more or less the same as OpenWRT. I did go through (LEDE) recovery once and found this fun issue:
root@(none):/tmp# sysupgrade -n lede-ar71xx-generic-archer-c7-v2-squashfs-sysupgrade.bin
Image metadata not found
killall: watchdog: no process killed
Commencing upgrade. All shell sessions will be closed now.
Failed to connect to ubus
root@(none):/tmp#
…because sysupgrade has different paths for failsafe vs not; and for some reason $FAILSAFE is not always set. Do this to work-around:
root@(none):/tmp# export FAILSAFE=1
root@(none):/tmp# sysupgrade -n lede-ar71xx-generic-archer-c7-v2-squashfs-sysupgrade.bin
Image metadata not found
killall: watchdog: no process killed
Commencing upgrade. All shell sessions will be closed now.
root@(none):/tmp# Connection to 192.168.1.1 closed by remote host.


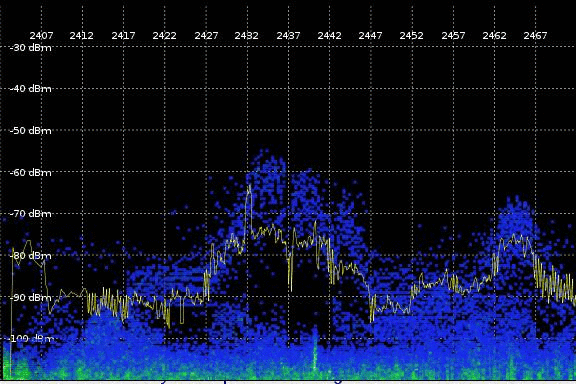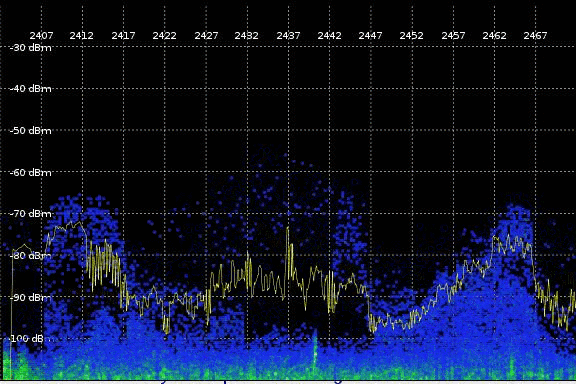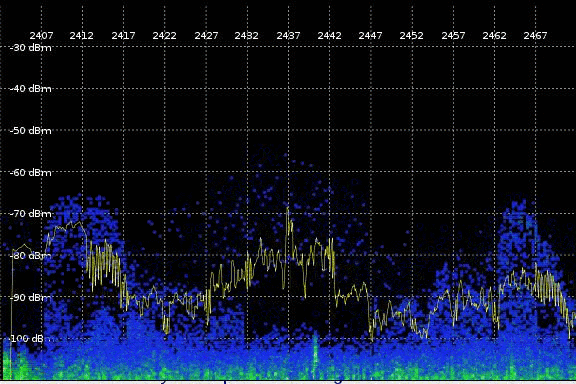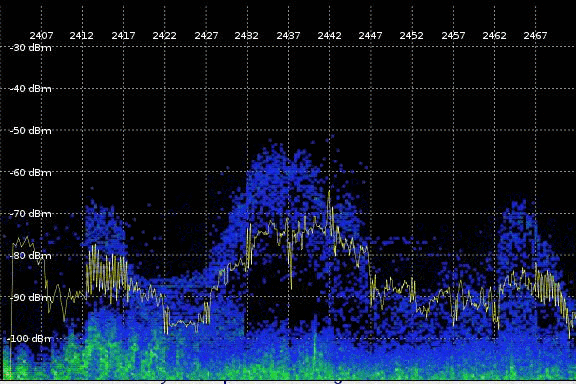{kind=link}