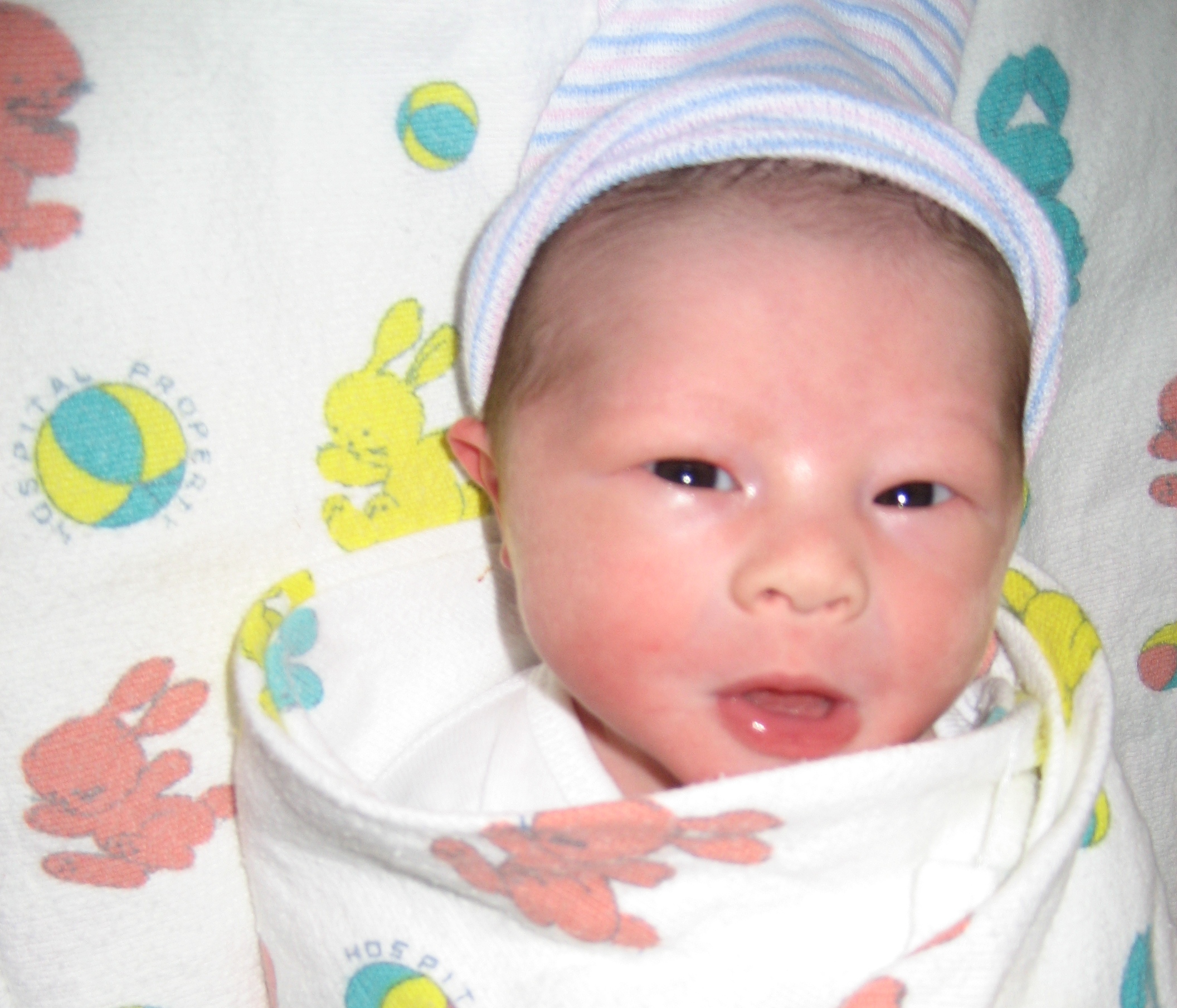
My most recent post, for those too lazy to follow the link and hit the “Reveal All” button, is a crossword puzzle announcing the birth of our third son, Samuel Yit-Mun Copeland. We’re over the moon with this new guy in our family. Here he is nearly asleep in my arms as I type this.

But now for something more boring.
I decided months ago that my typical geeky announcement would take the form of a crossword since I’ve been playing in that area recently (previous announcements: a manpage for Alex, an ascii-art crypto program for Ian). And why not make this puzzle interesting by constructing my first rebus puzzle?
A rebus puzzle is one in which a single square can have multiple letters. Part of the fun of solving is realizing at some point that an answer must be right, yet it cannot fit the available cells, so something really weird is going on. Then one curses the constructor and starts with a new set of assumptions.
Constructing such a puzzle is not too much harder than any ordinary puzzle, since all the rebus squares will be part of the themers that the constructor selects up front. Because of this, the fill software doesn’t even really need to care about rebuses — one can use any placeholder for the rebus squares and then edit the final crossword file to add in the full string.
Having lots of theme squares does constrain the grid somewhat, as does having a number of circles on top of that (in this case the circles spell out our new son’s name). But I cheated a little bit: I decided having any old separation between circles was fine as long as the components were all on the same line, and his name is short so that was no major obstacle. In the end I’m pretty happy with the fill considering the 55 theme squares + 20 circles.
Each time I make a puzzle, I also make a number of improvements to my filling software. I’ve long since forgotten whether the goal is building puzzles or building a puzzle builder.
I mentioned before that I had optimized the javascript filler to the point that it was potentially usable in a webapp; this webapp is now a thing. For this puzzle, I used that app as well as my interactive python command-line filler, which has some additional features like estimating the number of eventual solutions using more levels of look-ahead. Finally, I also used a version of the python filler that will take a completed grid and try to optimize it by repeatedly clearing sections of the grid and refilling it randomly.
There is still a good deal of performance work to do on the filler itself. The basic structure is still similar to the backtracking algorithm in QXW: bitmaps are used to filter available words for each cell, and we fill each entry starting with the entries with fewest fills. I made two minor changes in my version: the word list is initially sorted by score and indexed on length so that we can try highest scoring words first and eliminate comparisons against words that will never fit; and entire entries are filled instead of single cells so that score of an entire word is maximized.
I implemented my current algorithm from scratch in C, and it clocks in under half a second for my test puzzle: a little faster than QXW’s implementation and some 30x faster than the very same algorithm in javascript. In terms of LOC, they are roughly the same: 573 (python), 696 (javascript), 763 (C). You can watch them compete below.
So the javascript implementation is frightfully slow. Getting it down to the level of, say, two times the C code, would be a major win, but beyond my current level of js optimization know-how.
Besides that, there is likely some algorithmic optimization that could bring larger gains. Knowing that the “crossword fill problem” is an instance of SAT, I went off to read what Knuth had to say about it (Vol 4 fascicles 5-6), and, as usual, came away with a lot more to think about. The “word square” section is very similar to crossword filling, and indeed the algorithm is close to my existing search, except that it uses trie data structures to cut down on the number of possible words visited at each level. It’s unclear to me at present whether tries would be a win here given that we don’t always start filling with a prefix or suffix, but it could be worth an (ahem) try. Also I may look at branch-and-bound search pruning and parallel search at some point.