I’ve been looking at the sample drawing in speccy to try and speed it up. For a given frame, it renders about 10000 points as 9-pixel anti-aliased squares using Cairo, in Python. On my desktop (Debian stable, Nouveau driver) it gets a pokey 1 FPS.
My graphics knowledge is about 20 years old at this point, and while I did once know various arcane tricks on the hardware of the day, none of that is relevant now. So I know basically nothing about modern graphics. It is still not clear to me to what extent the 2D primitives use acceleration, and it doesn’t help much that, in as many years that I’ve been asleep on this topic, there seems to have been as many new APIs introduced and retired: today there are at least XRender, XAA, EXA, UXA, SNA, and Glamor — did I miss any?
Anyway, here are the results on my desktop from things that I’ve tried so far [1]:
test FPS
---- -------
orig (aa) 0.904780
no_aa 1.103061
no_cairo 8.372354
no_cairo_aa 2.408143
batched 19.873722
batched_aa 29.045358
batched_by_color 7.611148
batched_by_color_aa 14.856336
The tests are:
-
orig: the current code, where each rectangle is filled immediately in turn.
-
no_cairo: I skip Cairo completely and manually render to a GdkPixbuf internally, under the theory that draw function call overhead is the big killer
-
batched: using Cairo with one cr.fill() call for all of the rectangles. This means all are rendered with the same color, and as such could not actually be used. But it is interesting as a data point on batching vs. not.
-
batched_by_color: one cr.fill() call per distinct color
-
aa refers to having antialiasing enabled
Batching appears to make a huge difference, and binning and batching by color is the most performant usable setup. It’s not really difficult to batch by color since the colors are internally just an 8-bit intensity value, though in my quick test I am hashing the string representation of the float triples so it’s not as quick as it could be.
I don’t understand the performance increase on batching with AA applied. Perhaps this is an area where some sort of acceleration is disabled when AA is also disabled? This is a repeatable outcome on this hardware / driver.
Then I tested on my laptop and got these numbers (Debian Testing, Intel graphics):
test FPS
---- -------
orig (aa) 28.554757
no_aa 27.632071
no_cairo 9.954314
no_cairo_aa 2.958732
batched 43.917732
batched_aa 28.750845
batched_by_color 19.933492
batched_by_color_aa 19.803839
Here, just using Cairo is the best. My guess is batching by color is only worse because of the higher CPU cost of the hashing and the rather inefficient way I did it. Given the close performance of batched_aa and the original test though, batching done well probably isn’t going to make much difference.
Finally, I went back to the desktop and tried Nvidia binary drivers (oh, how I don’t miss those).
test FPS
---- -------
orig 6.586327
no_aa 15.216683
no_cairo 9.072748
no_cairo_aa 2.368938
batched 39.192580
batched_aa 27.717076
batched_by_color 18.681605
batched_by_color_aa 16.450811
It seems Nouveau still has some tricks to learn. In this case AA is, as expected, slower than non-AA. Overall, batching still seems to give a decent speedup on this hardware, so I may look into actually doing that. Moral of the story: use the laptop.
As for speccy, I actually had a use for it recently: I needed to see whether a particular testmode on ath5k was functional. Although I can’t really measure anything precisely with the tool, I can at least see if the spectrum looks close enough. Below is a snapshot from my testing, showing that in this testmode, the device emits power on 2412 MHz with a much narrower bandwidth than normal.
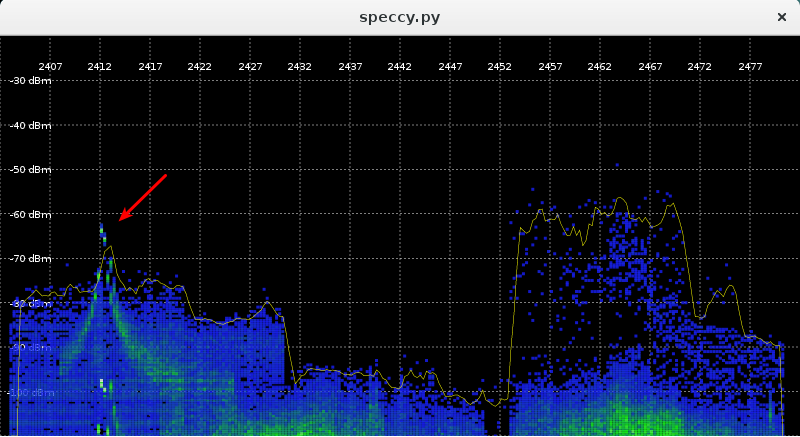
This matches, as far as I can tell, the spectrum shown on the NDA-encumbered datasheet.
[1] Approaches not tried yet: reducing the point count by partial redraws, using something like VBOs in GL, or rewriting parts in C. Feel free to let me know of others.