
New transcription: another Parker blues, Billie’s Bounce.

New transcription: another Parker blues, Billie’s Bounce.
For a while I’ve been using Amazing Slow Downer on the phone and PlayItSlowly on Linux for transcribing fast passages and to practice playing along with a tempo that I can manage. However, I frequently would like to just repetitively play a section a boatload of times while gradually increasing the BPM — without taking my hands off the fretboard to adjust a slider. So I wrote a thing.
#!/bin/bash
# play a segment of a song over and over, gradually
# increasing the tempo
file=$1
start=$2
end=$3
attempts=${4:-100}
start_speed=${5:-.5}
end_speed=${6:-1.0}
step=$(echo "scale=4; ($end_speed - $start_speed)/$attempts"| bc -l)
for t in $(seq $start_speed $step $end_speed); do
echo "*** $t ***"
mpv --no-video --start=$start --end=$end $file --o=/dev/stdout --of=ogg 2>/dev/null |
gst-launch-1.0 fdsrc fd=0 ! decodebin ! pitch tempo="$t" ! autoaudiosink >/dev/null 2>&1
done
Run it like so:
# between seconds 40 and 95, run 20 steps between half and full speed
./speedy.sh billies_bounce.ogg 40 95 20 .5 1
It would probably be nicer if the increase was logarithmic so you take smaller steps the faster it gets, but this worked out pretty well so far.
It’s kind of ridiculous to use mpv to segment the stream, but I couldn’t find a way to do windowing with just gst-launch (gnonlin seems to no longer be a thing) so, anyway, it works.
A belated happy 2024!
Most of my blog visitors are just bots spamming it with SQL injection attacks so this one goes out to any humans left out there. My job has been sucked into the generative AI vortex so I now work in an AI group at Amazon. If you’re reading this after an LLM became sentient and began rampaging… bwahahah, oh man, we’re nowhere near that… unless of course you are an investor and then yes sir I can magic your problem away.
As both of my human readers will know, in 2023 I posted a lot of jazz transcriptions and videos of myself playing them badly. This was very intentional as I decided to stop marveling at how one could make up solos on the spot, and to take some steps to learn the trick myself. My last guitar teacher (Berklee-trained) was very scale oriented, and so my improv really sounded like I was playing scales: very linear, no chromaticism and quite boring. It turns out I had a lot of misconceptions about how one does the thing — as I discovered, chord tones work better than scales; transcribing licks and solos by ear is not cheating but actually foundational; approach tones are key to getting the bebop sound. Besides transcribing, sitting down and working out all the arpeggios on a tune in one position, and composing a couple of solos really felt like they gave me a good boost in my playing. So I’m going to keep this going into 2024.
As a reference point, here’s where I am starting this year, on All the Things You Are in which the first chorus is composed and second half-chorus is improvised. Maybe I’ll check in again in 12 months and see how I improve.
November was a month to remember: we had Remembrance Day, and Guy Fawkes day, and well, just a whole lot of remembering things. I have been listening to a lot of hard bop, so naturally, I learned Remember, the Hank Mobley version.

Here’s take 1230912, post-workout edition, where I never could land that Ebm9 arpeggio in bar 49. I intentionally learned this in 5th position rather than 9th just to get some practice in a different area of the fretboard.
So I haven’t posted a transcription for September or October nor have I done much of anything this month, because I had COVID officially for the first time. Unofficially, who knows, probably at least twice by now?
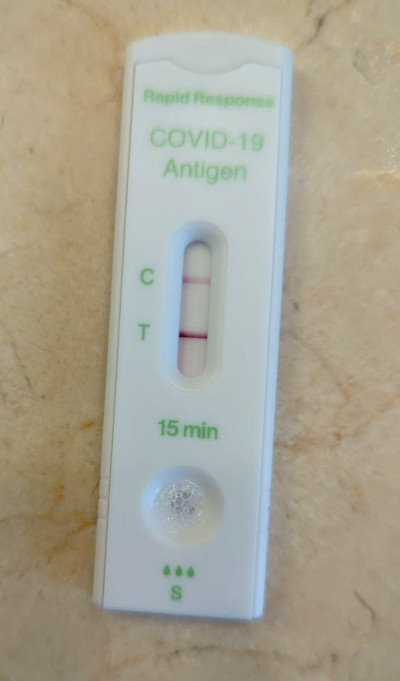
Someone needs to let BillG know the 5G has worn off at this point and we all need a refill… in 2-3 months time.
Anyway, I finally learned first couple of choruses of Bloomdido from my transcription and here I can be seen playing it not quite correctly so enjoy!
August’s tune is another Parker blues: Bloomdido. I transcribed all four choruses this time around, which was educational in that Parker repeats the same licks at the same place in more than one chorus, for example the C minor pentatonic figure in bars 21, 33, and 57 resolving to the 3rd of the F7. In two of those cases, he leads into it with a descending G mixolydian b9 b13 scale using a 3rd to b9 (B to A flat) intervallic leap which sounds amazing. The tempo is whipping by, so I didn’t really notice those until breaking it down, but there are a number of sounds worth stealing here.
I transcribed this tune by hand without my instrument during a 6 hour flight using a virtual piano and slow downer app; consequently I don’t actually know how to play it yet. I have maybe the first 2 choruses down at about half speed but will need a couple weeks of practice to memorize the rest and get it up to speed. So, no video yet!

July’s video is short and sweet. Rather than transcribe a solo this time around, I learned the head without actually writing it down and then composed a single chorus. The changes are a very bare bones B-flat blues, so this was an opportunity to check up on my voice leading and whatever bebop licks have found their way into my fingers.
A few observations on this process:
The recording is solo with no backing track or metronome. There are a couple of places, especially during rests, where I rush the tempo, and there’s a bar where I obviously failed to get my pick and left hand in sync, but on the whole I think it’s alright.
Time to interrupt the music posts with a check-in on this year’s garden. Now that the beds are freshly weeded and mulched, I can look at it without wincing. This year I did tomatoes: Black Krim, San Marzano (new); peppers: sweet, jalapeno, habanero; corn (new); Kirby cucumbers; garlic; gai lan; kale; carrots; potatoes; snap peas; pole beans; arugula; raspberries (new); strawberries (new); herbs: thai and sweet basil, thyme, chocolate mint, rosemary; flowers: marigolds and nasturtiums. I also just tossed a few brussels sprouts seeds in a pot to see if I can get anything with those in the fall.
Right now a few tomatoes have come in but most are still green. The corn just got its first set of silks. The berries aren’t doing anything at all. Last year’s A-frame trellis is holding up for the tomatoes and I made a small 3-post trellis for the cucumbers, which seem to be doing well (2 jars of refrigerator pickles so far). Loving straw as a mulch compared to grass clippings (weedy) and wood chips (doesn’t break down enough) that I’d used before.









Here we go again, this time trying a Charlie Parker Jazz blues. I thought blues was easy. Wrong!
I cut the video off early because I didn’t actually learn the 3rd chorus, just knew the next two bars or so.
Here’s the transcription — I know there are errors after having compared to the Omnibook but I’m going to leave it here for now. New month, new tune!

I didn’t get very far on a transcription this month, owing to having a new project at work and especially due to Return To Office commute erasing 3 hours daily of what might have been practice time. This month’s transcription is the first chorus of Miles Davis’s Four. Frankly, it still needs work and really wants the next few choruses to sound complete, but putting a pin in it for now as I am out of time.
I didn’t record this one, either.
